
Company
How we built a 24/7 accounting agent: durable LLM streaming
Written by

Rundong Lyu, Head of AI
A demo agentic chat app with LLM streaming is about a hundred lines of code. You open an SSE endpoint, call the model, and forward each delta to the browser as it arrives. Most tutorials stop there, and for a demo that’s fine. It stops being fine the moment the agent has to run in production, around the clock, on work that takes real time.
Refresh the page mid-response and the output is gone. Deploy the API server while a run is in flight and the run dies with the process. Close your laptop halfway through a 20-minute job and there’s no extra progress waiting when you come back. All of this happens because the demo ties the agent’s lifetime to an HTTP request, and HTTP requests are short-lived and fragile.
At Maxima we built Max, an AI agent for accounting work: reconciling transactions, generating journal entries, writing flux analysis. These tasks are multi-step, long-running, and expensive to lose. An accountant who starts a flux analysis should be able to close the laptop, step away, or check back later and find the run either still in progress or finished and ready for review. It should never just disappear.
So the design starts from one decision that drives everything else: the agent’s run has to be durable and independent of the browser. It runs in the background on infrastructure built to survive failures, and the browser is only a viewer. That viewer can also be something else later, like Slack or email.
Architecture overview
A 24/7 agent has a few requirements that all have to hold at once:
Durable: progress survives API deploys, worker crashes, and whatever the browser does.
Ordered: the frontend renders a strict event protocol, so out-of-order delivery breaks it.
Resumable: a client can reconnect and pick up exactly where it left off.
Multi-viewer: two tabs, or a laptop and a phone, can watch the same run.
Fast: none of that is allowed to slow down event delivery.
Here’s the overall shape:
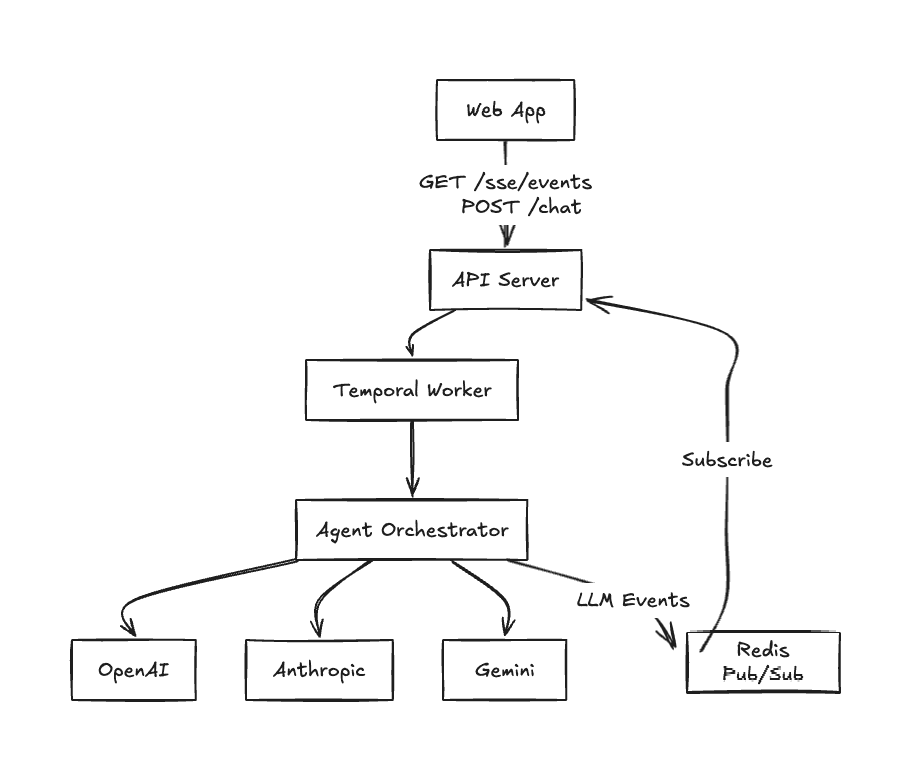
A user message hits the API server, which starts a background run and returns right away. It doesn’t hold the request open for the length of the work. The run executes inside a durable workflow engine — we use Temporal — which persists each step so a run can survive process restarts, retry failed steps, and continue whether or not anyone is connected. Inside the workflow, an agent orchestrator runs the actual loop: call the model, run any tools it asked for, feed the results back, and repeat, against whichever LLM provider the task needs.
The reason for that structure is that the run is a background process owned by Temporal rather than a function call inside an HTTP handler. The browser can connect and disconnect freely and the run carries on. That’s what 24/7 means in practice: the work lives somewhere durable, and the UI is just a window onto it.
While the run executes, the orchestrator emits a stream of events, and each event goes down two paths at the same time:
Live path: the event is published to Redis pub/sub, and API servers that have subscribed forward it to any open connection watching that thread. This keeps latency low and lets several viewers follow one run.
Durable path: the same event is written to Postgres asynchronously, in batches. This is the source of truth, and anything that needs history — a reconnect, a new tab, another client — reads from it.
The live path optimizes for latency and the durable path for not losing anything. Keeping the two consistent is where most of the work goes, and it breaks into four questions that the next sections take in turn: what the events have to satisfy, how we keep them ordered, why delivery runs at two speeds, and how a client catches up after a disconnect.
A strict event protocol
Start with what the events themselves have to satisfy. The UI renders them through a strict protocol, so their order and structure matter more than you’d expect.
For the events we use AG-UI, an open, provider-agnostic protocol for streaming agent activity to a UI. It already defines the things we’d otherwise have to design and version ourselves: text deltas, tool calls, reasoning, custom events, and run lifecycle markers.
The constraint that comes with it is ordering. Content deltas have to arrive between their message’s start and end markers, tool calls have their own bracketing, and every run follows a lifecycle. If an event is duplicated or arrives out of order, it isn’t a cosmetic problem; it puts the frontend’s state machine into a state it can’t recover from. So ordering is a hard requirement, and most of the rest of this post is about preserving it through reconnects, retries, and crashes.

Sequence numbers
Ordering comes down to a single number. Every event gets a sequence number, and it increases monotonically across the whole thread rather than resetting per run.
The per-thread part matters. A thread is a conversation that can span many runs over hours or days. A per-run counter would still work, but it pushes extra complexity onto both sides. The client couldn’t just store the last sequence number it saw; it would have to keep a (run id, sequence) pair, because sequence 42 on its own doesn’t say which run it belongs to, and it’s not safe to send back a bare 42 and assume the backend can figure out the run. The backend would then need a stable, total ordering of runs to resolve those pairs on reconnect. A single counter across the whole thread removes all of that: one integer fully describes a client’s position, and the client only has to remember that one number.
Assigning the number has to be safe across crashes. When a run starts, it reads the thread’s current high-water mark from Postgres and numbers new events from there, advancing the mark as it writes. If a run dies partway through and Temporal retries it, the next attempt continues from the recorded mark, so there are no collisions and no gaps that matter.
A nice side effect is that the sequence number fits into the SSE frame’s standard id field:
Browsers remember the last id they received and send it back in a Last-Event-ID header when they reconnect. That gives us the resume cursor for free: a reconnecting client asks for everything after 1083 and replays only what it missed instead of the whole thread.
Two delivery speeds
The two paths exist because live delivery and durable storage have opposite priorities, so each runs at its own speed. The obvious question is why we don’t just write every event to Postgres and stream from there. The reason is the live path can’t afford a database write per event. A long response is hundreds or thousands of events, and a synchronous write per token would put a round-trip in the token loop and a lot of write load on the table.
So the two paths run at different speeds. Publishing to Redis is effectively instant and happens per event, which is what the user sees. Writing to Postgres is batched, flushed regularly.
The trade-off is that if a worker crashes between flushes, up to one batch of events never reaches Postgres. This is acceptable as this is a tiny window and we have built-in retries which also cleans up partial events so the chat experience resumes nicely.
There’s a related step that keeps replay cheap as a thread grows. After a run finishes, we compact the hundreds or thousands of events into a handful of merged events. A client reconnecting to a thread with days of history then catches up in a few events instead of thousands, and the cursors still work because the numbers stay monotonic.
Replaying events on reconnect
When a client reconnects — a refresh, a dropped connection, a second tab — it has to catch up on what it missed and then continue streaming live. The obvious way is to do those in order: query Postgres for every event after the client’s last sequence number, send them, then subscribe to the live stream.
That isn’t quite enough, because there’s a gap between the two steps. The history query covers everything written up to the moment it runs, and the subscription covers everything from the moment it’s active. An active run emits events the whole time, so anything emitted in the small window between the query finishing and the subscription starting belongs to neither. On a mid-turn reconnect that window is small but gets hit constantly, and a missing event in a strict protocol desyncs the UI.
The fix is to swap the order and use the sequence number to handle the overlap. Subscribe first, so live events start buffering immediately, then query history:
With that order, an event emitted during the query lands in the buffer instead of being dropped. The client gets the replay from Postgres and then the buffered and live events. The two can overlap at the boundary, where the same event shows up in both, but the sequence number sorts that out: the stream remembers the highest sequence it has sent and skips anything less than or equal to it. A duplicate is easy to drop; a gap is the thing that breaks the protocol, and subscribing first makes gaps impossible.
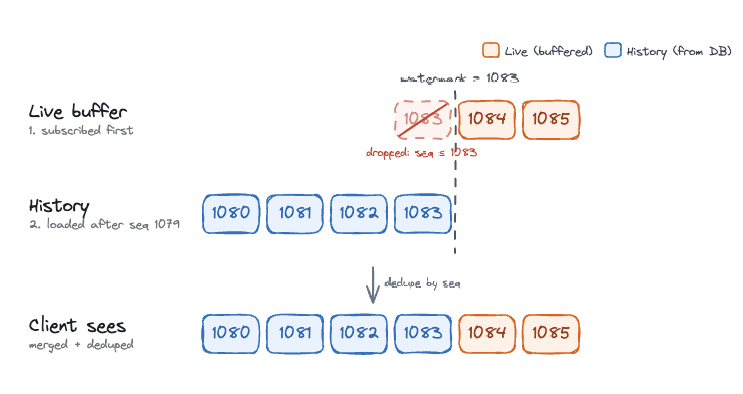
Every reconnect then follows the same path: reconnect with the last sequence number, replay after it, subscribe first, dedupe at the boundary.
Retries the user never sees
One thing took longer to get right than expected: durable execution and a strict event protocol don’t combine on their own.
Temporal’s retries are good for reliability. A model blip, a flaky tool, or a crashed worker, and it just runs the step again without our code having to handle it. But running the step again also means emitting its events again. The frontend sees a run start, half a message, then a second run start and the same message from the top, and the protocol’s state machine has no way to interpret that.
Two things keep retries from reaching the client.
The first is checkpointing. As a turn runs, it records what it has finished — input saved, model call done, which tool calls have returned — and Temporal persists that record. A retried turn reads it and resumes instead of starting over: finished steps are skipped, finished tools aren’t run again, and events that were already emitted aren’t emitted again. A turn that times out nine minutes into a ten-minute job picks up at minute nine.
The second is draining on cancel. When a user hits stop, the run is cancelled, but it may still be holding an unflushed batch, and the sequence mark has to include that batch before the run ends. So a cancel doesn’t kill the run immediately; it lets the in-flight work flush its last batch first. Otherwise the cancelled run’s final events could collide with the next run’s first ones.
The common thread is that every failure path — retry, cancel, disconnect — has to keep the same guarantee the normal path has: each event reaches the client once, in order. As soon as one path can break that, the protocol’s strictness works against you instead of for you.
Was it worth it?
It’s a lot of moving parts for something a tutorial does in a hundred lines: Temporal, Redis, Postgres, a sequence scheme, a careful reconnect handler, checkpointing, and drain-on-cancel.
What it buys us is that runs survive deploys, crashes, refreshes, and closed laptops. Any number of viewers — a browser, a second tab, Slack, email — can attach to a run and see the same stream with no gaps. Retries and cancels happen all the time in production and users don’t see them, because the event stream stays clean. Max ends up behaving less like a request that might drop and more like something that keeps working while you’re away, which is what an agent doing real accounting work needs.

Insights, news and content
The latest
See all


