Agentic AI
Accuracy in accounting: Why AI needs more than intelligence
Written by

Akshaya Srivatsa, CPO
For the first time, AI systems can demonstrate expert-level knowledge of accounting. Frontier models such as GPT-4 and Claude now score above passing thresholds on sections of the CPA exam. Across broad benchmarks like MMLU, they approach 90 percent accuracy across 57 domains, including professional accounting. On paper, these systems understand revenue recognition, lease accounting, and double-entry bookkeeping at a level comparable to trained professionals.
And yet, when these same models are applied to real accounting workflows, they fail. In the AccountingBench study conducted by Penrose, frontier models were tasked with closing the books for a real SaaS company over a twelve-month period using actual transaction data. Early results looked promising.
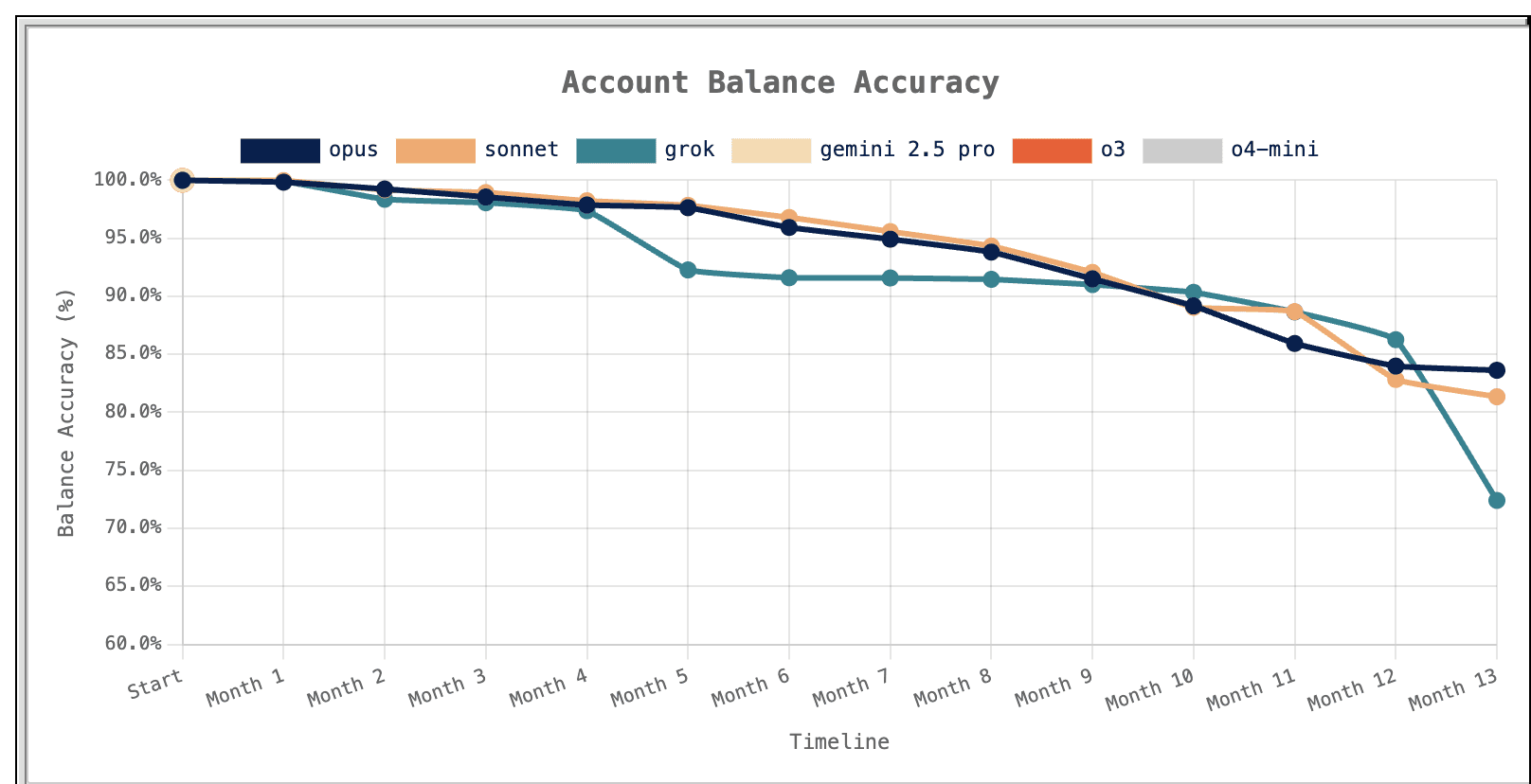
Source: Penrose blog
Some models maintained accuracy above 95 percent for the first few months. By year-end, balances had diverged by more than 15 percent. Every model failed. Not because the models lacked accounting knowledge, but because they could not maintain accuracy over time.
This is the central problem in AI accounting today. It is not about intelligence. It is about reliability.
The gap between knowledge and accuracy
Accounting has always been sensitive to error. Manual processes carry baseline error rates of 1 to 4 percent in data entry alone. At scale, this results in hundreds of incorrect entries entering the ledger during each close cycle. Many of these are false positives that consume hours of investigation. Others go undetected until audit.
AI appears to offer a solution. If models can reason about accounting concepts at an expert level, they should reduce error rates and improve consistency. In practice, they do not.
The AccountingBench results make this clear. The models did not fail immediately. They failed over time, as small inconsistencies accumulated across workflows. A misclassification in one period became precedent in the next. Outputs were reused as inputs without validation. Errors propagated silently. By the end of the year, the books had drifted materially from reality. Knowledge is not the same as accuracy.
Why benchmarks do not reflect reality
The disconnect between benchmark performance and production performance is structural. Benchmarks such as the CPA exam and MMLU are designed as self-contained problems. Each question provides all required information. There is a single correct answer. There is no dependency on prior state.
Accounting does not operate this way. Every action in accounting affects future actions. A journal entry posted in January changes the trial balance in February. A classification error in one period influences reporting, reconciliation, and variance analysis in subsequent periods. Workflows are interconnected and stateful.
Accuracy is not determined by a single correct answer. It is determined by consistency across time. The models tested in AccountingBench behaved like test-takers solving independent questions. Accounting requires a system that maintains continuity across hundreds of interdependent actions.
This is why a model can pass the CPA exam and still produce financial statements that are materially incorrect.
What breaks in practice
The limitations of generalized AI in accounting are not theoretical. They appear immediately when these systems are applied to real workflows:
The first failure mode is lack of grounding. Models generate outputs based on patterns in training data and prompts, not on live financial systems. Without direct access to the general ledger, subledgers, or source systems, they are effectively reasoning in abstraction. This leads to hallucinated account mappings, incorrect balances, and explanations that are not tied to actual transactions.
The second is the absence of validation. Accounting workflows require deterministic checks at every stage. Journal entries must tie out. Reconciliations must balance. Variances must reconcile to underlying activity. Generalized models do not enforce these constraints. They produce plausible outputs, but they do not verify them.
The third is the lack of workflow continuity. Accounting is not a single task. It is a sequence of dependent steps. Data is collected, transformed, validated, posted, and then used again in downstream processes such as reconciliations and flux analysis. Generalized systems do not maintain state across these steps. Each interaction is effectively stateless, which allows errors to propagate silently.
The fourth is the absence of controls. In production environments, accounting systems operate within strict governance frameworks. Segregation of duties, approval workflows, audit trails, and policy enforcement are not optional. They are required. Generalized AI systems do not natively operate within these constraints.
Individually, each issue introduces risk. Together, they make the system unreliable at scale.
This is particularly evident in analytical workflows. Take flux analysis as an example. A generalized model may identify the largest drivers of variance and generate a plausible explanation. But it does not validate whether those drivers are correctly classified, whether they reflect expected behavior, or whether prior assumptions were accurate. The output appears correct, but it is not grounded in accounting reasoning.
Why accuracy degrades over time
The most important insight from AccountingBench is that these errors are not isolated. They accumulate.
Accounting systems are iterative. Outputs from one period become inputs to the next. A misclassified transaction in January affects the opening balances in February. An incorrect accrual flows into future variance analysis. An explanation that is not grounded in data becomes precedent for future reasoning.
Without validation, these errors are not corrected. Without memory, they are not even recognized as inconsistencies. Over time, the system drifts. This is fundamentally different from traditional software failure. It is not a bug that can be fixed once. It is a structural issue that emerges from how the system operates.
In controlled demos, where datasets are small and conditions are simplified, this is not visible. In production environments, where volume and variability are high, it becomes the dominant failure mode. Penrose documented this pattern precisely. The models that failed did not lack intelligence. They lacked continuity, context, and the ability to validate their own prior outputs against a persistent source of truth. When figures did not reconcile, models attempted to compensate by finding unrelated transactions rather than surfacing the discrepancy. The result was books that drifted further from reality with each passing month.
Accuracy is a systems problem
The lesson from these results is not that AI cannot do accounting. It is that AI cannot do accounting reliably without the right system around it. Accuracy is not a property of the model. It is a property of the system in which the model operates.
What determines whether outputs are reliable is not just the model’s reasoning capability, but the structure that governs how that reasoning is applied. Systems that produce reliable accounting outputs separate reasoning from execution. The model orchestrates workflows and handles unstructured analysis, while deterministic systems perform calculations such as allocations, eliminations, and currency conversions. The model does not do the math. Deterministic operators do:
They enforce policy-bound logic. Every action is constrained by company-specific accounting policies, including entity-level configurations, capitalization thresholds, intercompany treatment, and approval requirements. This prevents the drift observed in AccountingBench.
They operate on validated source data. Transactions are pulled directly from upstream systems through native integrations and normalized before any agent touches them. The system operates on clean, transaction-level data with full lineage, not on copied files or prompt inputs.
They maintain continuous reconciliation. Matching and validation occur before and after posting, not just at month-end. Breaks are identified while they are still small and correctable.
They surface exceptions as they occur. Outliers, mismatches, and unexpected patterns are identified in real time, focusing human attention on true exceptions.
They embed human review into the workflow. Agent-prepared work is inspected, approved, and only then posted. This is not a workaround for imperfect automation. It is a necessary control in any accounting system.
Together, these elements form a control architecture that ensures accuracy over time.

From assistance to preparation
The shift is not from humans to AI. It is from AI assisting humans to AI preparing work for human review. In this model, agents operate across the full accounting workflow. They collect data, apply accounting logic, generate outputs, and validate results. Humans review, approve, and handle exceptions.
This changes the role of the accountant. Instead of spending time preparing journal entries, reconciling accounts, and investigating variances manually, they focus on oversight, validation, and judgment. More importantly, it changes how accuracy is achieved. Errors are no longer introduced at every step of manual preparation. They are constrained within a system that enforces validation, context, and controls at every stage.
Accuracy becomes a property of the system, not an outcome that must be monitored.
The right way to think about AI in accounting
The question is not whether AI can perform accounting tasks. The CPA exam results demonstrate that the knowledge exists. The AccountingBench results demonstrate that knowledge alone is insufficient. The correct question is whether the system surrounding the AI is designed to make that knowledge reliable at production scale, over time, and within audit constraints.
A general-purpose model connected to financial data will produce outputs that appear correct most of the time. In accounting, that is not enough.The most costly errors are not obvious mistakes. They are subtle inconsistencies that compound over time.
Systems designed for accounting operate differently. They enforce controls, maintain context, validate continuously, and integrate human oversight into the workflow. They separate reasoning from computation, enforce policies rather than infer them, and ensure that every output is traceable and auditable.
The model contributes reasoning. The system enforces correctness. And in accounting, anything less will not survive the audit.
Move closer to an audit-ready, real-time close

Request demo
Insights, news and content
The latest
See all


